Q: Does our algorithm guarantee to return an exact motif?
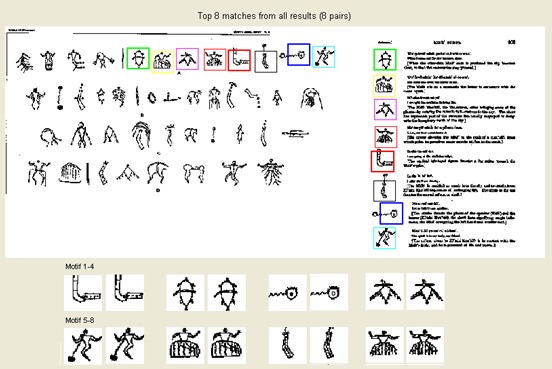
A: The answer is no. We cannot guarantee that our algorithm will return the exact motif but, in practical, two windows of the motif is usually hashed in to the same bucket. We do multiple time of random hashing and we union the results; if the motif hash into the same bucket once (very high chance), bingo! In that case, our algorithm will return the correct answer. Examples of approximate motifs from real dataset are shown below and you can download more here.
 |
 |
 |
 |
 |
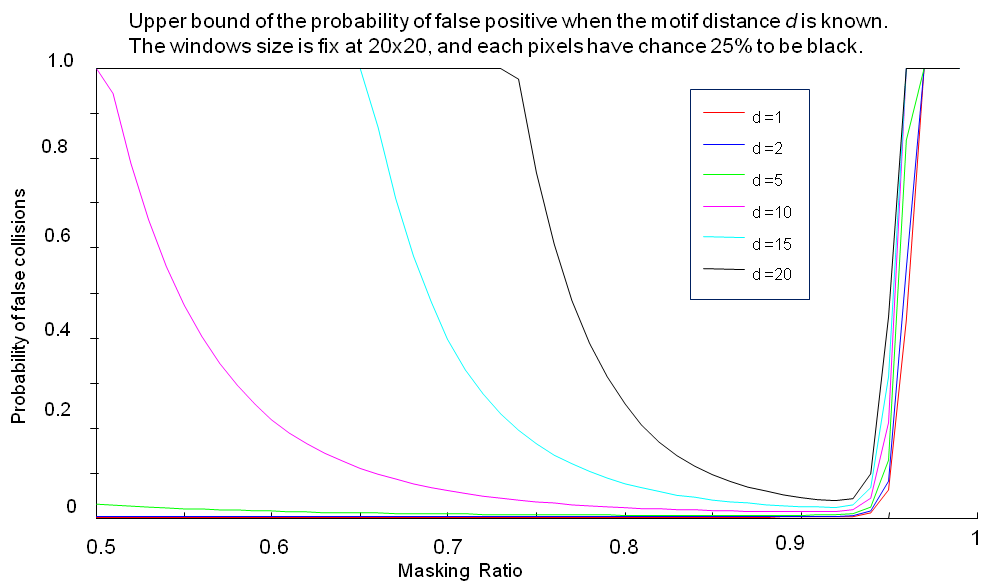
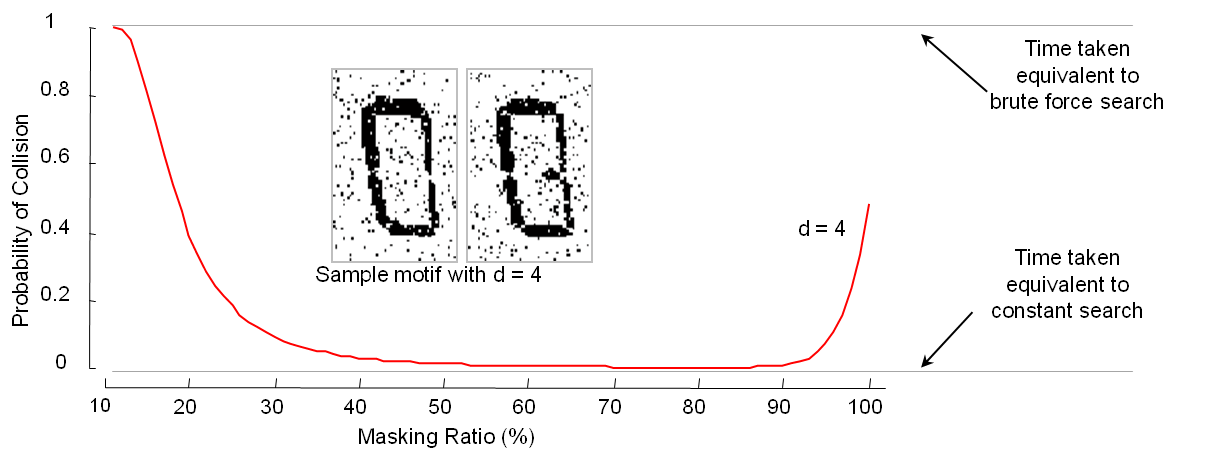
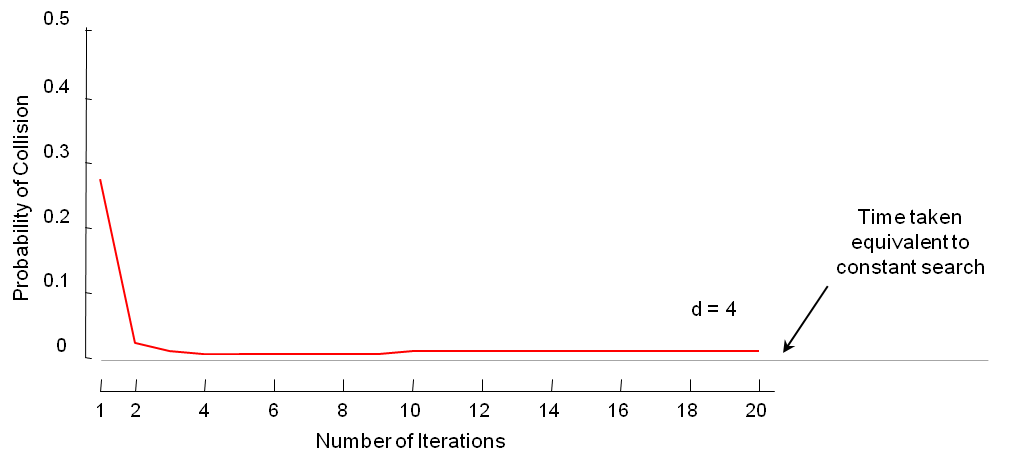
Q: If user want to be guaranteed that an exact motif will be discovered with probability 99%, what is the number of false positive?
A: Our analysis shows that if the motif distance is known, we can bound the number of false positive; this number is usually small although we do random projection many times. You can see more in our theoretical analysis slide For quick review, please see figure below. Note that we can also allow our algorithm set parameters automatically to obtain this upper bound by using equation in our analysis.
 |
 |
 |
Q: What is more related area for this work between data mining and image processing?
A: It is absolutely in data mining area. It is true that the input of our algorithm are documents which may contain a lot of images. The image processing techniques are required to do preprocessing, and that's it. After converting the cleaned documents to ternary (or binary) matrix, all stuffs after that are in data mining area. We do 2-step hashing which contains downsampling part and random removing part. We also propose an easy but non-trivial method to locate the potential windows which can reduce the search space dramatically.
The main objective are to discover motifs on large documents; for example, at the end of this page, we show examples motifs across two heraldry books of size 221 pages, and 450 pages. To best of our knowledge, most work in image processing area do similarity search with many fine-tuning techniques and it cannot apply to large documents. Then, our method is more related to data mining area than image processing area.
Q: Is our algorithm scale invariant?
A: The short answer is no. However, because of downsampling technique, motifs which contain two windows in small different scale, say 10-15%, can be discovered, as you can see the tigers in previous question are in different scale.
Q: Is our algorithm rotation invariant?
A: No, but it is not much hard to change the hash function to support scale invariance. However, before that, a new distance measure which supports a rotation invariance is also required.











