|
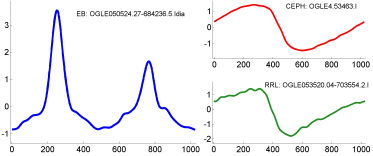
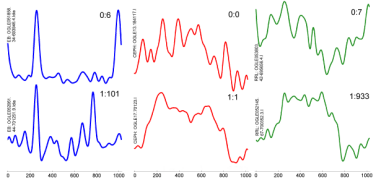
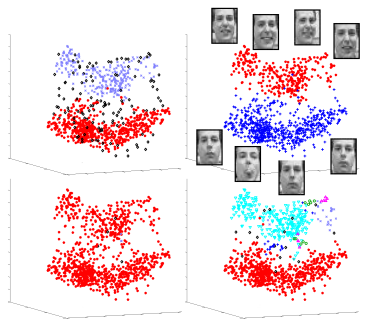
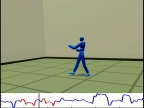
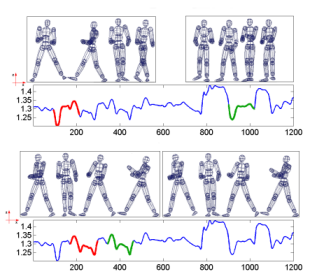
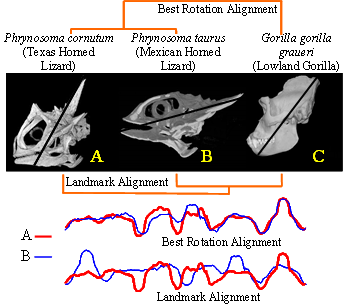
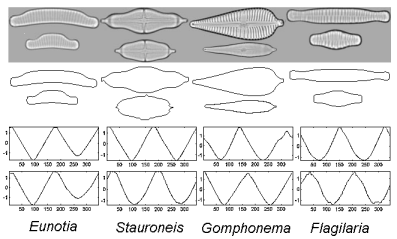
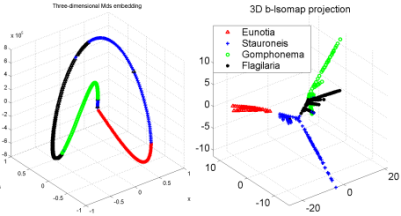
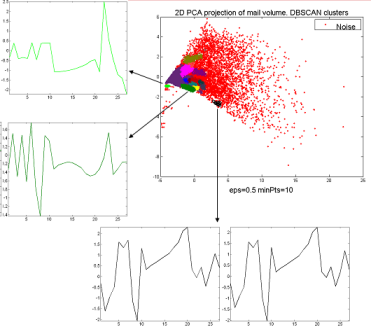
The project resulted in a publication at ICDM 2007: Disk aware discord discovery: finding unusual time series in terabyte sized datasets Description (from the abstract of the paper): The problem of finding unusual time series has recently attracted much attention, and several promising methods are now in the literature. However, virtually all proposed methods assume that the data reside in main memory. For many real-world problems this is not be the case. For example, in astronomy, multi-terabyte time series datasets are the norm. Most current algorithms faced with data which cannot fit in main memory resort to multiple scans of the disk/tape and are thus intractable. In this work we show how one particular definition of unusual time series, the time series discord, can be discovered with a disk aware algorithm. The proposed algorithm is exact and requires only two linear scans of the disk with a tiny buffer of main memory. Furthermore, it is very simple to implement. We use the algorithm to provide further evidence of the effectiveness of the discord definition in areas as diverse as astronomy, web query mining, video surveillance, etc., and show the efficiency of our method on datasets which are many orders of magnitude larger than anything else attempted in the literature. |
Source code and executables: |
cpp_discords.zip, java_discords.zip, matlab_discords.zip |
Sample data files: |
data_discords.zip |