- The "naive" Breadth First Search (BFS) Technique
- The Random Breadth-First-Search (RBFS) Technique
- Searching using Random Walkers
- Directed BFS and the Most Results in Past (RES) Heuristic.
- Using Randomized Gossiping to Replicate Global State
- Searching Using Local Routing Indices
- Centralized Approaches
- Depth-First-Search and Freenet
- Consistent Hashing and Chord
- Design Issues of the ISM mechanism.
- Components of the ISM mechanism.
- The Search Mechanism
- Peer Profiles
- Peer Ranking
- Distance Function: The Cosine Similarity
- Random Perturbation
- Performance of the BFS Algorithm
- Performance of the Random BFS Algorithm
- Performance of the Intelligent Search Mechanism
- Simulating Peer-to-Peer Systems
- Modeling Large-Scale Peer-to-Peer Networks
- dataGen - The Dataset Generator
- graphGen - Network Graph Generator
- dataPeer - The Data Node
- searchPeer - The Search-Node
- Implementation
- Reducing Query Messages
- Digging Deeper by Increasing the TTL
- The Discarded Message Problem
- Reducing the Query Response Time
- Improving the Recall Rate over Time
List of Tables
- Top 20 Queries on Gnutella in June 2002. (inappropriate queries marked with '_'). The total set includes 15 million query messages and the last column the percentage out of all the queries.
- An example of a Compound Routing Index at node
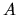 .
The first row presents
the local index of A while the rest rows indicate how many documents are reachable
through each neighbor.
.
The first row presents
the local index of A while the rest rows indicate how many documents are reachable
through each neighbor.
- The Peer's Profile Mechanism snapshot. It shows from which neighbors (i.e. {P1,P2...}) each queryhit came from and on which time (timestamp).
- A sample XML record from a dataPeer's XML repository.
- PDOM-XQL and Retrieving an XQL ResultSet of all articles of a given country.
- The country-hosts.graph file for "australia" shows the outgoing connections that will be established during initialization.
- Distribution of Gnutella IP Addresses to Domains.
- Sample set of unstructured queries posted by searchPeer. Each keyword consists of at least 3 characters and the keywords are sampled from the dataset.
List of Figures
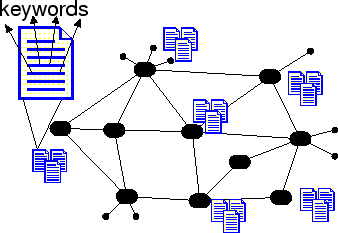
- Information Retrieval in P2P systems.
- Searching in a peer-to-peer network with Breadth First Search BFS: Each peer forwards the query to all its neighbors.
- Searching in a peer-to-peer network with Random Breadth First Search RBFS: Each peer forwards the query to a subset of its neighbors.
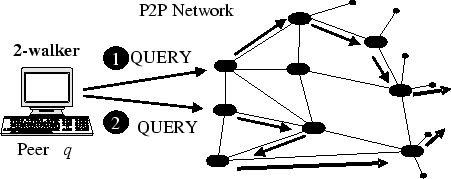
- Searching using a 2-walker. Each node forwards the query to a random neighbor.
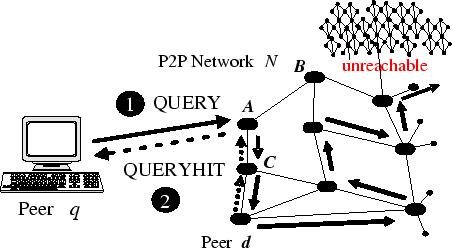
- The
 RES heuristic is able to identify stable neighbors, neighbors connected with many others
as well as neighbors which are not overloaded. It however fails to explore nodes which
contain content related to a query.
RES heuristic is able to identify stable neighbors, neighbors connected with many others
as well as neighbors which are not overloaded. It however fails to explore nodes which
contain content related to a query.
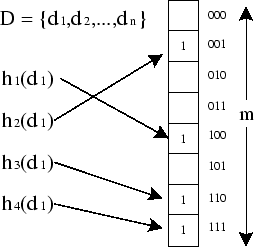
- A Bloom Filter that uses 4 hash functions and has a size of m=8 bits.
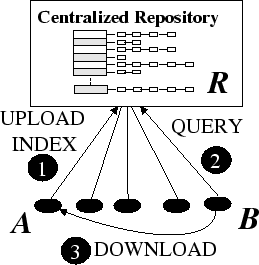
- In centralized approaches there is usually an inverted index
 over
all the documents in the collection of the participating hosts .
over
all the documents in the collection of the participating hosts .
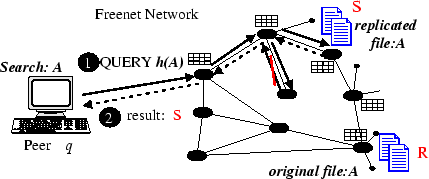
- Freenet uses an intelligent Depth-First-Search mechanism along with caching of keys/objects at intermediate nodes. The intermediate caching achieves redundancy as well as anonymity.
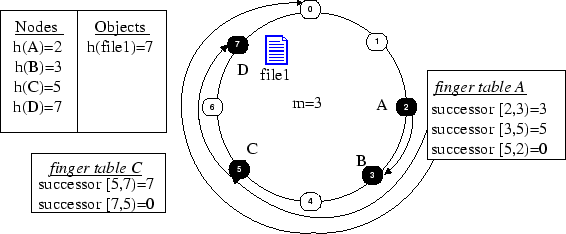
- Chord uses a consistent hashing scheme to organize objects and nodes in a virtual circle. The proposed algorithm provides an efficient way for looking up objects.
- Searching in a peer-to-peer network with the Intelligent Search Mechanism ISM: Each peer uses the knowledge it obtains from monitoring the past queries to propagate the query messages only to a subset of the peers.
- With Random Perturbation we give node the opportunity to break the cycle (A,B,C,D) in which
queries may get locked and therefore allow it to explore a larger part of the network and
find the correct answers.
- Visualization of a random graph with 104 peers & degree=4, with graphGen.
- Visualization of a random graph with 104 peers & degree=2, with graphGen. The graph is connected which is not typical for graphs with a small degree.
- The Components of a dataPeer Brick.
- The Components of searchPeer.
- Analysis of Gnutella Network Traffic: Message breakdown by Message Type.
- Messages used by the 4 Algorithms for 10x10 queries (TTL=4)
- Recall Rate by the 4 Algorithms for 10x10 queries (TTL=4)
- Messages used by the 4 Algorithms for 10x10 queries (TTL=5)
- Recall Rate by the 4 Algorithms for 10x10 queries (TTL=5)
- The Discarded Message Problem.
- Time used as a fraction of the time used in BFS for the 4 Algorithms in the 10x10 experiment (TTL=4).
- Time used as a fraction of the time used in BFS for the 4 Algorithms in the 10x10 experiment (TTL=5).
- Messages used by the 4 Algorithms for 400 queries (TTL=4)
- Recall Rate by the 4 Algorithms for 400 queries (TTL=4)
Introduction
Peer-to-peer (P2P) networks are increasingly becoming popular because they offer opportunities for real-time communication, ad-hoc collaboration [12] and information sharing [23,11] in a large-scale distributed environment. Peer-to-peer computing is defined as the sharing of computer resources and information through direct exchange. The most distinct characteristic of P2P computing is that there is symmetric communication between the peers; each peer has both a client and a server role. The advantages of the P2P systems are multi-dimensional; they improve scalability by enabling direct and real-time sharing of services and information; enable knowledge sharing by aggregating information and resources from nodes that are located on geographically distributed and potentially heterogeneous platforms; and, provide high availability by eliminating the need for a single centralized component. In this thesis we consider the information retrieval problem in the P2P networks. Assume that each peer has a database (or collection) of documents (see figure 1.1) which represents the knowledge of the peer. Each peer shares its information with the rest of the network through its neighbors. A node searches for information by sending query messages to its peers. Without loss of generality we assume that the queries are collections of keywords and that a querying peer is interested in finding all the documents that contain a set of keywords. A peer receiving a query message evaluates the constraint locally against its collections of documents. If the evaluation is successful, the peer generates a reply message to the querying peer which includes the identifier of all the documents that correspond to the constraint. Once a querying peer receives responses from all the peers it afterwards decides which documents to download. Each document can be associated with a unique documentId (using for example a hash function on the contents of a document) to uniquely identify the same documents from different peers. Note that searching based on the file contents is not possible in most current P2P systems today [4,27]. In those systems searching is done using file identifiers instead (such as the name of the file or the documentId). Although this allows deployment of efficient search and indexing techniques it restricts the ability of P2P users to find documents based the contents of the documents. To solve the search problem, most current systems either rely on centralized control [23] or on query message flooding mechanisms [11]. The second approach (broadcasting the query) can easily be extended to solve the problem we consider here. This can be achieved by modifying the query message to include the query terms instead of the desired file identifier. This approach is best suited for unstructured peer-to-peer networks, since all functionality (including indexing and resource sharing) is decentralized. Such systems do not use peers with special functionality. Gnutella is an example of such a system. In hybrid peer-to-peer networks [16,28], one (or possibly more) peers have additional functionality in that they become partial indexes for the contents of other peers. Each peer, as it joins the network uploads a list of its files to the index server. Commercial information retrieval systems such as web search engines (e.g. Google [13]) are using a similar approach for indexing the web. These are centralized processes that exploit large databases and parallel approaches to process queries, and work extremely well. In the P2P information retrieval context however, they have several disadvantages. The biggest disadvantage is that the index needs to be an inverted index over all the documents in the network. This means that the index node has to have sufficient resources to setup and maintain such settings. Although hardware performance and costs have improved, such centralized repositories are still expensive and prohibitive in dynamic environments where nodes are joining and leaving.
Motivation
Our proposed algorithm works well in environments where there is high locality of similar queries. In order to see what the real trends are, we made an extensive analysis of the network traffic found in a real P2P network [30]. In June 2002 we crawled the Gnutella network with 17 workstations for 5 hours and gathered
| # | Query | Occur. | % | # | Query | Occur. | % |
| 1 | divx avi | 11 | divx | ||||
| 2 | spiderman avi | 12 | spiderman | ||||
| 3 | p___ mpg | 13 | xxx avi | ||||
| 4 | star wars avi | 14 | capture the light | ||||
| 5 | avi | 15 | buffy mpg | ||||
| 6 | s__ mpg | 16 | g__ mpg | ||||
| 7 | Eminem | 17 | buffy avi | ||||
| 8 | eminem mp3 | 18 | t___ mpg | ||||
| 9 | dvd avi | 19 | seinfeld v_____ | ||||
| 10 | b______ | 20 | xxx mpg |
Our Contribution
In this thesis we consider a fully distributed technique for addressing the information retrieval problem in pure P2P networks. We propose the Intelligent Search Mechanism (ISM), an efficient, scalable but yet simple mechanism for improving the information retrieval problem in P2P systems. Our algorithm exploits the locality of past queries by using well established techniques from the Information Retrieval field. To our knowledge no previous work has been done using similar techniques. Finally our technique is distributed and a node can make autonomous decisions without coordinating with any other peers which therefore both reduce networking and processing costs.
The thesis is organized as following: Section 2 discusses related work and a number of different techniques for Information Retrieval in P2P systems. Section 3 presents the components of the Intelligent Search mechanism. In section 4 we make an analytical study of the compared techniques. Section 5 describes PeerWare, our distributed simulation infrastructure which is deployed on 50 machines. Section 6 presents our experimental results under various scenarios and section 7 concludes this thesis.
Information Retrieval in P2P Networks
In this chapter we consider a number of different techniques to search in P2P networks. The techniques presented in sections 2.1 to 2.7 are appropriate in the context of Information Retrieval since users can search based on keywords. In section 2.8 and 2.9 we present two distributed lookup protocols which allow peer-to-peer applications to efficiently locate a node that stores a particular object. These two techniques are not applicable in the context of Information Retrieval since we are searching based on keywords rather than identifiers. For the next sections we consider a network of
The "naive" Breadth First Search (BFS) Technique
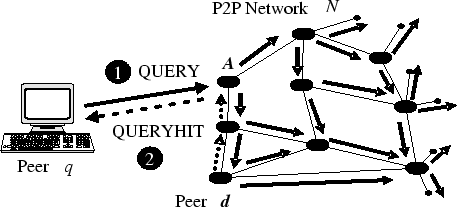 |
The Random Breadth-First-Search (RBFS) Technique
In [20] we propose and evaluate the Random Breadth-First-Search (RBFS) technique that can dramatically improve over the naive BFS approach. In RBFS (see figure 2.2) each peer
 |
Searching using Random Walkers
In [19] a search technique based on random walks is presented. In the proposed algorithm each node forwards a query message by selecting a random neighbor and the query message is called a walker. In order to reduce the time to receive the results the idea of the walker is extended to a k-walker which after
Directed BFS and the Most Results in Past (RES) Heuristic.
The most closely related technique to our work is presented in [29]. The authors present a technique where each node forwards a query to some of its peers based on some aggregated statistics. The authors compare a number of query routing heuristics and mention that the The Most Results in Past (
 |
Using Randomized Gossiping to Replicate Global State
In PlanetP [7] an approach for constructing a content addressable publish/ subscribe service that uses gossiping of global state across unstructured communities is proposed. Their approach uses Bloom filters to propagate global state across the community. A Bloom filters [2] is a method for representing a set
Searching Using Local Routing Indices
| @A | Number of Documents | Database Related | Network Related | Theory Related |
| A | 300 | 20 | 80 | 0 |
| B | 100 | 20 | 0 | 10 |
| C | 1000 | 0 | 300 | 0 |
| D | 200 | 100 | 0 | 150 |
In [6] Crespo et al, present a hybrid technique which addresses the issue of building and maintaining local indices which will contain the "direction" towards the documents. More specifically three different techniques, namely Compound Routing Indexes (CRI), Hop-Count Routing Index (HRI) and Exponentially aggregated RI (ERI) are presented and evaluated over different topologies like tree, tree with cycles and powerlaw. The ideas deployed in the routing indexes schemes can be thought as the routing tables deployed in the Bellman Ford or Distance Vector Routing Algorithm, which is used in many practical routing protocols like BGP and the original ARPAnet [17]. More specifically a node knows which peers will lead him to the desirable amount of documents but it doesn't know the exact path to the documents. As shown in table 2.1 in
Centralized Approaches
In centralized systems there is an inverted index over all the documents in the collection of the participating hosts. These include commercial information retrieval systems such as web search engines (e.g., Google, Yahoo) that are centralized processes, as well as P2P models that provide centralized indexes [23,28]. Figure 2.6 illustrates the usage of centralized systems such as Napster [23]. In the first step node
 |
Depth-First-Search and Freenet
Freenet [4] is a distributed information storage and retrieval system designed to address the concerns of privacy and availability. The system is transparently moving, replicating and deleting files based on usage patterns and its search algorithm does not rely on flooding or centralized indexes.
 |
Consistent Hashing and Chord
In this section we introduce Chord [27] which is a distributed lookup protocol that uses a consistent hashing scheme. Chord like other Distributed HashTable (DHT) algorithms allows peer-to-peer applications to efficiently locate a node that stores a particular object. In Chord one basic operation, lookup(key), returns the address (i.e. IP) of the node storing the object with that key. This operation allows nodes to put and get files in the community only based on their key. In the proposed technique an m-bit identifier is used to hash both Nodes* and Objects* . Although Chord is not restricted to any particular hash function the scheme deploys SHA1 which is widely used and in which collision of two keys is difficult. The next operation is to assign each Node N and Key k in a one- dimensional circular key space which has
 |
The Intelligent Search Mechanism (ISM)
In this section we present the Intelligent Search Mechanism (ISM) which is a new mechanism for information retrieval in the P2P networks. The objective of our algorithm is to help the querying peer to find the most relevant answers to its query quickly and efficiently rather than finding the larger number of answers. Keys to improving the speed and efficiency of the information retrieval mechanism is to minimize the communication costs, that is, the number of messages sent between the peers, and to minimize the number of peers that are queried for each search request. To achieve this, a peer estimates for each query, which of its peers are more likely to reply to this query, and propagates the query message to those peers only.
Design Issues of the ISM mechanism.
The design objectives of the Intelligent Search Mechanism were the following:
- Maintain Only Local Knowledge.
Approaches that maintain global
state tend to have a significant communication overhead which makes them
inefficient for dynamic environments were the participants are not known a' priori.
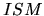 uses only local state information of a constant size which therefore minimizes
the communication overhead.
uses only local state information of a constant size which therefore minimizes
the communication overhead.
- Avoid Data Replication.
Distributed HashTable approaches usually distribute
resources along with the keys to nodes in a network. That approach has a significant
overhead for nodes that join the network only for a short period of time.
Consider for a example a node
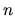 that joins the network for a few minutes.
This node is assigned by the global hashing scheme some
that joins the network for a few minutes.
This node is assigned by the global hashing scheme some 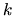 files which will
be transferred to . The size of the files might be in the order of
several Megabytes yielding therefore a significant communication cost.
Since decides to leave the network after a few minutes the network
did not gain anything by replicating the k files.
on the other hand assumes that no replication takes place in a network of nodes.
This is also a reasonable assumption from the social point of view
(i.e. "Why would some node share resources used by somebody else?"), although
we don't claim that DHTs are appropriate for file sharing applications.
files which will
be transferred to . The size of the files might be in the order of
several Megabytes yielding therefore a significant communication cost.
Since decides to leave the network after a few minutes the network
did not gain anything by replicating the k files.
on the other hand assumes that no replication takes place in a network of nodes.
This is also a reasonable assumption from the social point of view
(i.e. "Why would some node share resources used by somebody else?"), although
we don't claim that DHTs are appropriate for file sharing applications.
- Reduce Messaging.
Although brute force techniques such as Breadth-First-Search (section 2.1)
are simple since they don't require any form of global knowledge,
they are expensive in terms of messages.
addresses this issue by intelligently forwarding query messages
to nodes that have a high probability of answering the particular queries.
- Route Queries to Relevant Content.
Although approaches such as Random Breadth-First-Search (section 2.2) or
the Random Walkers (section 2.3) significantly reduce messaging
they do not address the issue of finding the most relevant content.
on the other hand uses the
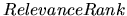 of a peer to forward a
query to the peers that have the highest potentiality of answering
the particular query.
of a peer to forward a
query to the peers that have the highest potentiality of answering
the particular query.
Components of the ISM mechanism.
The Intelligent Search mechanism for distributed information retrieval consists of four components:
- A Search Mechanism to send the query to the peers. This is the only mechanism used by a node to communicate with its peers. It is the same mechanism employed by the Gnutella protocol for communications between peers.
- A Profile Mechanism, that a peer uses to keep a profile for each of its neighbors. The profile keeps the most recent past replies coming from each neighbor.
- RelevanceRank, which is a peer ranking mechanism that a peer
runs locally using the profiles of its peers and the specific
query. The mechanism ranks the peers in
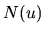 in order to send the search query
to the most likely peers.
in order to send the search query
to the most likely peers.
- A Cosine Similarity function that a peer uses locally to find the similarity between different search queries.
The Search Mechanism
Assume that a peer initiates a search to find documents about a specific topic. Since it is initiating the search, we call him the querying_peer. The querying_peer generates a Query message that describes his request, finds which of his peers are most likely to provide an answer (using the profile mechanism and the peer ranking mechanism) and broadcasts the Query message to those peers only. If a peer receives a query message we call him the receiver_peer. If the receiver_peer can provide an answer, it returns an answer to the requesting querying_peer. It also propagates the Query message only to those of his peers it considers most likely to provide the answer (Figure 3.1). To provide a termination condition so that the messages are not propagated indefinitely in the network, the querying_peer sets a bound on the depth of the recursion. When a reply QueryHit message is sent back to the querying_peer, the peers in the answer path (which is the same as the query path) record the query and the name of the peer that provided the answer in a
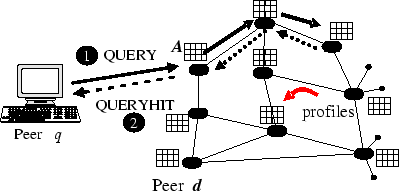 |
Peer Profiles
To decide to which peers a query will be sent, a node ranks all its peers with respect to the given query. The number of peers that a query will be sent is a parameter that is defined by the user. To rank its peers, each node maintains a profile for each of its peers. The profile contains the list of the most recent past queries, which peers provided an answer for a particular query as well as the number of results that a particular peer returned. Although logically we consider each profile to be a distinct list of queries, in the implementation we use a single
| Query Keywords | GUID | Connections & Hits | Timestamp |
| Columbia NASA Nevada | G568FS | ( |
10000000 |
| Elections Usa Bush | OF34QA | NULL | 10001000 |
| ... | ... | .... | ... |
| Superbowl San Diego | LQI65D | ( |
10012300 |
Peer Ranking
For each query received by a node
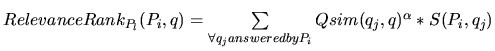
Distance Function: The Cosine Similarity
In order to find the most likely peers to answer a given query we need a function
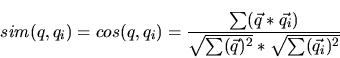
Random Perturbation
One problem of the technique we outline above is that it is possible for search messages to get locked into a cycle. The problem is that the search will fail then to explore other parts of the peer-to-peer network and may not discover many results.
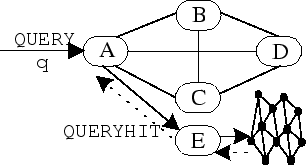 |
Performance Analysis of the Proposed Techniques
In this section we describe the characteristics of the proposed techniques, in comparison with the Gnutella protocol which is a BFS Algorithm with some TTL (Time-to-Live) parameter that limits the depth that a query travels. We concentrate on the recall rate, that is, the fraction of documents our search mechanism retrieves compared to the other mechanisms, and the efficiency of the technique, that is, the ratio of number of messages that the different techniques use for the same search.
Performance of the BFS Algorithm
Assume a graph
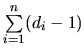 times.
The reason for this is that
when a given node times.
times.
The reason for this is that
when a given node times.
Performance of the Random BFS Algorithm
We first consider the performance of the modified random BFS technique where each peer selects a random subset of its peers to propagate a request (that is, here a profile of its peers is not used). In a P2P network with a random graph topology, this mechanism searches the nodes of the graph more efficiently (that is, it sends fewer messages) than the BFS algorithm. Consider a random graph
Performance of the Intelligent Search Mechanism
The previous discussion indicates that propagating a query to a random subset of one's peers is more efficient when searching nodes in a P2P network with random graph topology than using the Gnutella protocol (with respect to the total number of messages). However this approach is approximate, and cannot guarantee that all nodes in
- The algorithm uses fewer messages compared to the standard Gnutella strategy, and scales better with respect to the size of the network (because it can search a larger network using the same number of messages)
- The size of the profiles is proportional to the number of direct connections per peer. This is likely to remain small (constant) even for very large networks.
- The scheme uses the combined knowledge about the peers, and adapts and modifies its behavior as each peer learns more information about its peers. On the other hand, peers do not have to export any information about their databases.
PeerWare Simulation Infrastructure
In order to benchmark the applicability and efficiency of our algorithms we have implemented PeerWare, a distributed middleware infrastructure which allows us to benchmark different routing algorithms over large-scale P2P systems. Probing different query-routing algorithms over middleware P2P systems can be interesting from many points of views:
- In real settings the scalability of various query-routing algorithms may be explored to the fullest extend since there are no assumptions which are typical in simulation environments.
- Moreover many properties, such as network failures, dropped queries due to overloaded peers and others may reveal many interesting patterns.
- Finally, in a middleware infrastructure we are also able to capture the actual time to satisfy queryhits.
Simulating Peer-to-Peer Systems
The Anthill Project [3] developed at the University of Bologna uses Jtella [21] Java API as a basis for building a fully customizable API for the Gnutella network. The aim of the project is to create a simulation framework which will allow researchers to develop and validate new P2P algorithms. The system itself is inspired from the biological metaphor of Ant colonies. They mention that real Ants are known to locate the shortest path to a food source using as only information the trails of chemical substances called pheromones deposited by other ants. Moreover they mention that although individual ants are unintelligent and have no explicit problem solving capability, ant colonies manage to perform several complicated tasks with high degrees of consistency. Although the project doesn't emphasize particularly on P2P case studies, it is worth it to mention that they are currently using their framework to investigate the properties of the Freenet [4] algorithm by modifying its protocol and comparing the performances of different implementations. Their framework intends to obtain:
- Information about the queries performed by users and their distribution. More specifically they aim to find popular queries or keywords that may be exploited to implement intelligent caching algorithms.
- Information about the files stored in the Gnutella network, which might be obtained by logging the Gnutella QUERYHIT messages.
- Information about the shape of the network, which might be obtained by
actively probing Gnutella PING and PONG messages. They also intend to
take advantage of the Gnutella PUSH messages in order to partially
investigate which files are downloaded by users.
Modeling Large-Scale Peer-to-Peer Networks
Jovanovic et al. study [15], of Modeling Large-scale Peer-to-Peer Networks, is to our knowledge the only comprehensive work done in the area of modeling Peer-to-Peer systems. Their study reveals that Gnutella has some important structural properties, such as small-world properties and several power-law distributions of certain graph metrics. They mention the famous Milgram's experiment [22] which was conducted in the early 1960's, and in which a number of letters, addressing a person in the Boston area, were posted to a randomly selected group of people in Nebraska. Each person who received the letter forwarded it to someone that they knew, on a first name basis. As many of the letters finally reached the designated person, the average number of hops observed was between five and six. Their study reveals that a similar, small world property existed in the Gnutella Network. More specifically in 5 different snapshots of the Gnutella Network they found that the diameter of the network ranged from 8-12. In their work they have also discovered that the Gnutella Network obeys all four of the power-laws described in Faloutsos et al. work. [8]. More specifically they found, on a Gnutella snapshot gathered on the
Jovanovic's study on the same snapshot of data also revealed that the Outdegree Exponent
Their study finally shows that the Hop-Plot Exponent
dataGen - The Dataset Generator
dataGen is a Reuter's [25] dataset transformer which takes as input the Reuter's set of documents and transforms it into a collection of XML documents by some of the following criterions, which are found in the collection:
{Date, Topics, Places, People, Orgs, Companies}.
For our experiments we have chosen the Places criterion which clusters the documents by country. There were 104 different countries with at least 5 documents, and the total number of documents for these 104 countries was
The objective of the Dataset Generator was to generate sets of documents about specific topics in order to represent the specialized knowledge of each peer. The dataset generator is implemented in Java and uses IBM's XML Parser [14] along with the GMD-IPSI XQL engine [10], which is a Java based storage and query application for large XML documents. The GMD-IPSI XQL engine offers the Persistent Document Object Model (PDOM) class which implements the full W3C-DOM API on indexed, binary XML files. Therefore documents are parsed only once and stored in binary form for future usage. The cache architecture of the engine makes the engine a Memory-Disk structure highly appropriate for large XML documents which can't physically fit in main memory. PDOM has increased performance as compared to the Document Object Model (PDOM) implemented by most of the XML Parsers and which tries to build an in-memory data structure of the XML documents and which usually has a great performance penalty. The XQL processor is used to query PDOM files by providing both the PDOM Document and the query to be processed (Table 5.2).
graphGen - Network Graph Generator
| #UCR Random Graph generator |
| country=australia |
| ip=283-20.cs.ucr.edu |
| port=10002 |
| #Peers that "australia" should connect to |
| china=283-20.cs.ucr.edu,10013 |
| india=283-25.cs.ucr.edu,10008 |
| vietnam=283-28.cs.ucr.edu,10016 |
| lebanon=283-25.cs.ucr.edu,10021 |
| mexico=283-26.cs.ucr.edu,10000 |
| spain=283-26.cs.ucr.edu,10024 |
| chile=283-20.cs.ucr.edu,10012 |
graphGen, is the component responsible for generating the simulation topology. More specifically, it generates a set of configuration files which can be read by the various nodes that comprise the simulation network topology. graphGen starts out by reading graph.conf, which contains among others the following parameters:
- Outdegree of a node, which is used in the case a random graph.
- Topology of the P2P network (e.g. random graph).
- IP List of hosts that will participate in a simulation.
This allows us to map a logical topology (e.g. Node1 - Node10) to many
different IP topologies
On table 5.4 we can see the distribution of domains from a set of 300,000 IP addresses found in the Gnutella Network. These results, which we gathered in [30], will be used in our future work, to build a more realistic network topology that will again facilitate the evaluation of our query routing techniques. These alternatives can easily be embodied in our system since it requires only changes on graphGen rather than the whole system. grahGen, also generates output which can be piped into Visualization Tools, such as GraphViz [24], and generate graphical representations (i.e. directed or undirected graphs) of the network topology.
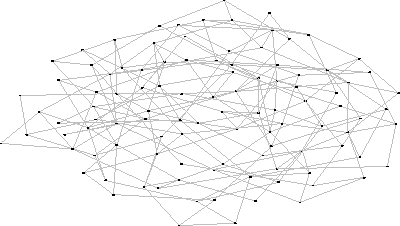
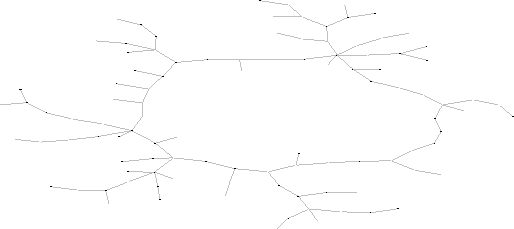 |
dataPeer - The Data Node
dataPeer, is a P2P client which maintains a local repository of XML documents. Typical P2P clients answer to queries only based on filename descriptions. dataPeer on the other hand queries its repository each time a query arrives. dataPeer consists of three sub-components : 1) The PDOM-XML Manager, which queries efficiently the local xml repository with XQL, 2) A P2P Network module, which provides an interface to the rest of the network and which implements the various query-routing algorithms, and 3) Routing State Structures, which capture the implementation specific logic of the proposed query-routing algorithms. Each dataPeer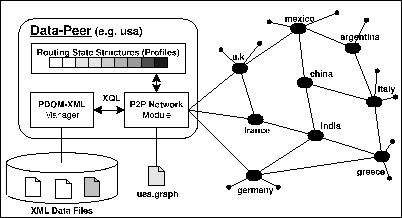
searchPeer - The Search-Node
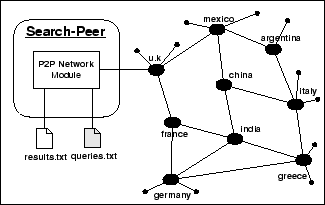
searchPeer (Figure 5.4), is a P2P client which submits a number of queries in a PeerWare network and harvests the returned results. In contrast with dataPeer, searchPeer consists only of a Network Module and a Result Logging Mechanism. Besides logging the number of results it also gathers a number of other statistics such as the number of nodes answered to a particular query and the time to receive the results. searchPeer reads upon initialization the keywords.txt file(see table 5.5), which contains a set of unstructured queries sampled randomly from the dataset.
| # | Query |
| 1 | AUSTRIA INTERVENE DOES DOLLAR |
| 2 | APPROVES MEDITERRANEAN FINANCIAL PACKAGES |
| 3 | ABANDONS DEFEATS STRONGHOLD AFTER |
| 4 | AGREES PEACE NEW MOVES |
| 5 | AID KENYA DEBT MOI |
| 6 | AND CALLS FORCE NATO |
| 7 | BUDGET BIG RULING JAPAN |
| 8 | BANGLADESH PROPOSALS TAX GOVERNMENT |
| 9 | BANGLADESH FOR GRANT BRIDGE |
| 10 | BANS ZIMBABWE FOR OILSEEDS |
These queries are submitted sequentially with a small sleep interval between consecutive queries. The reason for that choice was twofold; firstly it would allow each host to have enough time to process a query request (e.g. a query message wouldn't stuck in some queue and suffer from long queuing delays) and secondly it would make sure that the query response time would have some meaningful value and that it would not be a function of how much traffic is currently in the network. The searchPeer maintains a different session for each query it sent out. In that way it is able to listen to queryhits that were delayed and which arrive after some new query was already send out.
Implementation
The PeerWare infrastructure is implemented entirely in Java. Its implementation consists of approximately
Experiments
In order to compare our intelligent search mechanism with the other Query-routing algorithms described in section 2, we have built a decentralized newspaper network. The newspaper is organized as a network of dataPeers; each dataPeer maintains a set of articles related to a particular country. In that way each dataPeer shares some specialized knowledge (i.e. documents related to the country). dataPeers are connected among them using a pre-specified random topology. We then use a searchPeer to connect to a single point in the network and perform a number of queries. Our experiments were deployed with 104 dataPeers running on a network of 20-50 workstations, each of which has an AMD Athlon4 1.4 GHz processor with 1GB RAM running Mandrake Linux 8.0 (kernel 2.4.3-20) all interconnected with a 10/100 LAN connection. Our evaluation metrics were: (i) the recall rate, that is, the fraction of documents our search mechanism retrieves compared to the other mechanisms, and (ii) the efficiency of the technique, that is, the ratio of number of messages used to find the results.
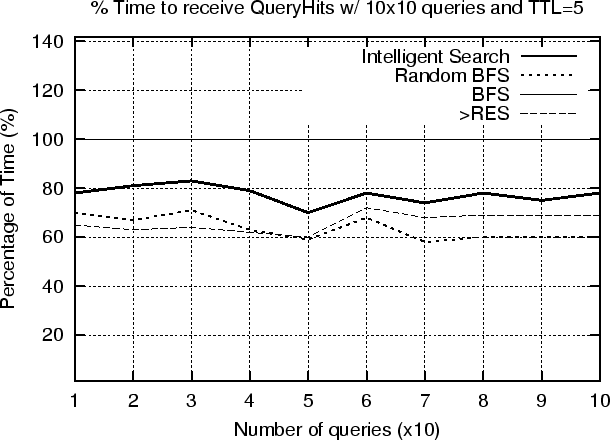
Reducing Query Messages
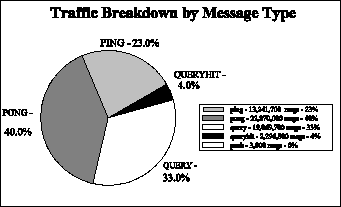
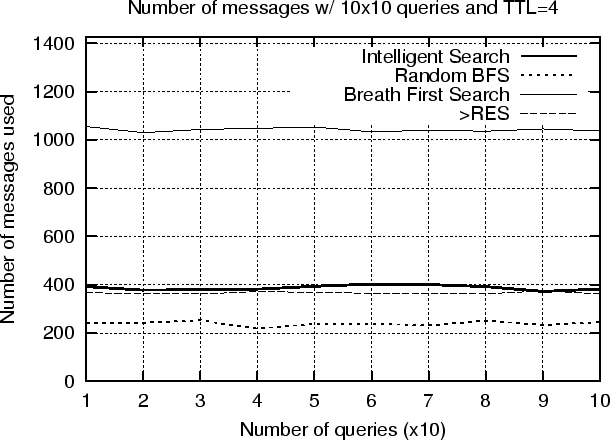
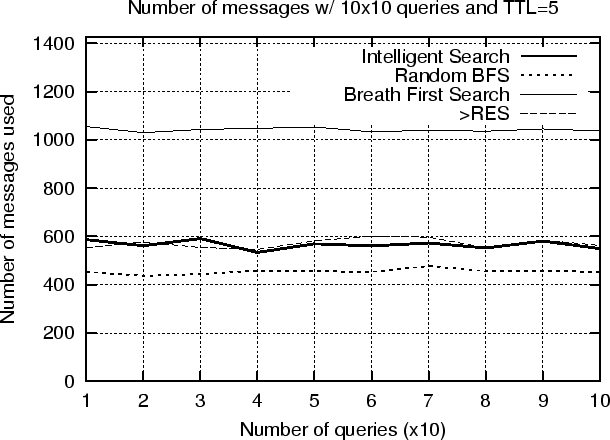
Our prior analysis on the Gnutella Network Traffic (figure 6.1) revealed that 37% of the network messages where spent on query/queryhits pairs. The ultimate goal of a P2P network is the resource discovery part. We can see from the pie-chart that the Ping/Pong messages, which are used for the host discovery part, occupy a significant share of the total network traffic. This is attributed to weak network connections in the Gnutella Network. In this work we don't consider host discovery related issues. Our goal is to decrease the number of Query/QueryHit messages while being able to discover the same resources. In our first experiment we performed 10 queries, each of which was run 10 consecutive times over a PeerWare of 104 nodes where each host has a degree of 8. We allow a 5 second interval between each query in order to avoid congesting the network. The queries are keywords randomly sampled from the dataset. In this set of experiments we measured the number of messages used and the percentage of documents found in the case where the query messages has TTL=4. Figure 6.2 shows the number of messages required by the 4 query routing techniques. The figure indicates that Breadth-First-Search (BFS) requires almost 2,5 times as many messages as its competitors with around 1050 messages per query. BFS's recall rate is used as the basis for comparing the recall rate of the other techniques and is therefore set to 100%. Random Breadth-First-Search (RBFS), the Intelligent Search Mechanism (ISM) and the Most Results in the Past (
|
=2.4in
|
|
=2.4in
|
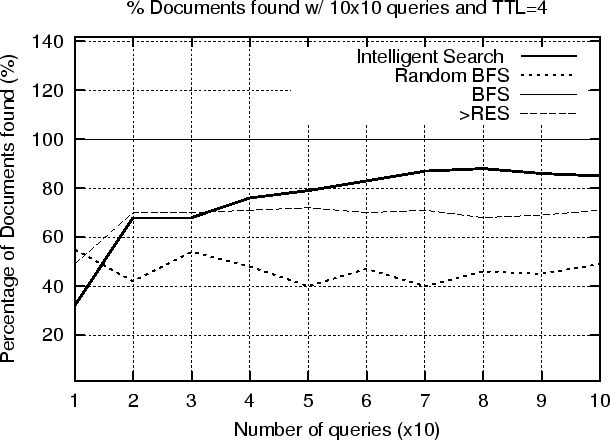
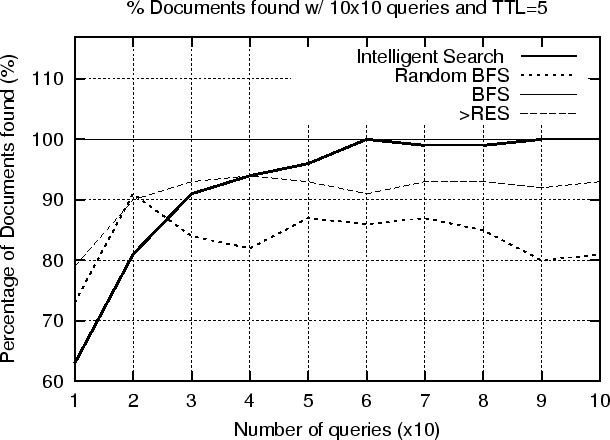
Digging Deeper by Increasing the TTL
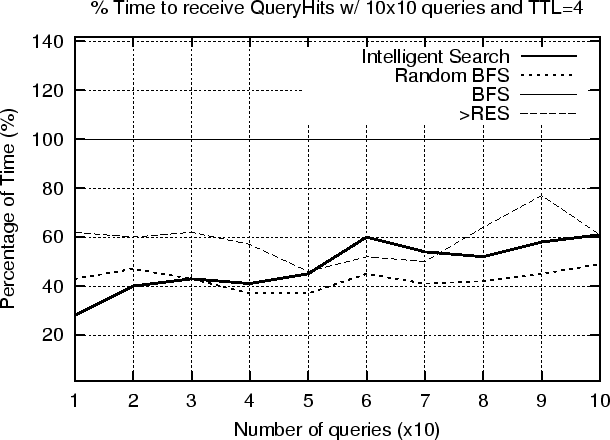
In the second experiment we investigated what is the effect of increasing the TTL parameter to our results. Figure 6.5 shows that by increasing the value of the time_to_live field of the search requests (TTL = 5) the Intelligent search mechanism discovers almost the same documents with what BFS finds for TTL = 4. More specifically, our experimental results show that our mechanism achieves 99% recall rate (figure 6.5) while using only 54% (figure 6.4) of the number of messages used in BFS. Again, the recall rate increases as the number of queries increases over time. Another important observation is that the results for both RBFS and ISM are consistent with our analysis, and show that it is possible to search the majority of the P2P network with significantly fewer messages than the brute force algorithm.
|
=2.4in
|
|
=2.4in
|
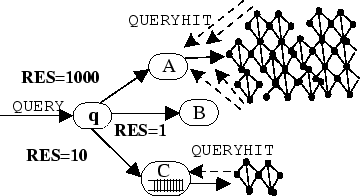
The Discarded Message Problem
We define the Discarded Message Problem (DMP) (see figure 6.6) in the following way: A node
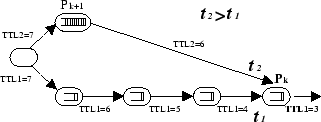
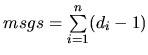 for
for
Reducing the Query Response Time
|
=2.4in
|
|
=2.4in
|
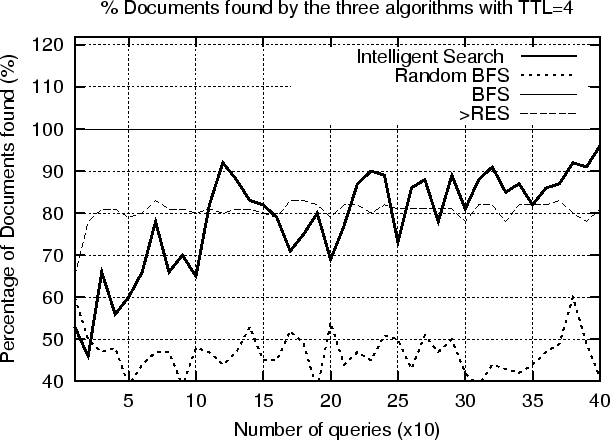
Improving the Recall Rate over Time
In the previous experiments we used 10 queries which are performed 10 consecutive times. This scenario suits well the ISM algorithm since the queries are correlated. In this experiment we use 400 queries which are randomly sampled from the dataset. The sampling is biased since we choose to pick approximately 4 queries per country (which consequently also means per dataPeer), for 104 dataPeers. With this assumption we make sure that the queries will refer to all the dataPeers rather than only a subset of them. Each query
|
=2.5in
|
|
=2.5in
|
Conclusions & Future Work
Peer-to-Peer systems are application layer networks which enable networked hosts to share resources in a distributed manner. Such systems offer several advantages in simplicity of use, robustness and scalability. In this thesis we address the problem of efficient Information Retrieval in such systems. We analyze a number of different techniques and then present the Intelligent Search Mechanism. The Intelligent Search mechanism (ISM) uses the knowledge that each peer collects about its peers to improve the efficiency of the search. The scheme is fully distributed and scales well with the size of the network. ISM consists of four components: A Profile Mechanism which logs query-hits coming from neighbors, a Cosine Similarity function which calculates the closeness of some past query to a new query, RelevanceRank which is an online ranking mechanism that ranks the neighbors of some node according to their potentiality of answering the new query and a Search Mechanism which forwards a query to the selected neighbors. We deploy and compare ISM with a number of other distributed search techniques. Our experiments were performed with real data over PeerWare, our middleware simulation infrastructure which is deployed on 50 workstations. Our results indicate that ISM is an attractive technique for keyword searching in Peer-to-Peer systems since it achieves in some cases 100% recall rate by using only 54% of the messages used in the flooding algorithm. The results further show that ISM improves over time because nodes learn more information about their neighbors as time elapses. ISM achieves therefore a better recall rate than its competitors, although its initial performance is similar to them. Lastly we have shown that ISM requires approximately the same Query Response Time (QRT) with its two main competitors RBFS and
Bibliography
- 1
-
American National Standards Institute
American National Standard X9.30.21997: Public Key Cryptography for the Financial Services Industry - Part 2: The Secure Hash Algorithm (SHA-1) (1997)
- 2
-
B. H. Bloom.
"Space/Time Trade-Offs in Hash Coding with Allowable Errors",
Communication of the ACM, 13(7):422-426, 1970
- 3
-
Ozalp Babaoglu, Hein Meling and Alberto Montresor
"The Anthill Project"
In Proceedings of the 22th International Conference on Distributed Computing Systems (ICDCS '02), Vienna, Austria, July 2002.
- 4
-
Ian Clarke, Oskar Sandberg, Brandon Wiley, and Theodore W. Hong,
"Freenet: A Distributed Anonymous Information Storage and Retrieval System"
in Designing Privacy Enhancing Technologies: International Workshop on Design Issues in Anonymity and Unobservability, LNCS 2009, Springer: New York (2001).
- 5
-
Clip2, "Gnutella: To the Bandwidth Barrier and Beyond", November 6, 2000,
http://www.clip2.com/gnutella.html
- 6
-
A. Crespo, H. Garcia-Molina.
Routing Indices For Peer-to-Peer Systems.
Proc. of Int. Conf. on Distributed Computing Systems, Vienna, Austria, 2002.
- 7
-
Francisco Matias Cuenca-Acuna and Thu D. Nguyen.
"Text-Based Content Search and Retrieval in ad hoc P2P Communities",
International Workshop on Peer-to-Peer Computing, Springer-Verlag Vol:2376, May 2002
- 8
-
Michalis Faloutsos, Petros Faloutsos, and Christos Faloutsos.
On power-law relationships of the internet topology.
In SIGCOMM, pages 251-262, 1999. - 9
-
L. Fan, P. Cao, J. Almeida, and A. Z. Broder,
"Summary cache: A scalable wide-area web cache sharing protocol,"
IEEE/ACM Transactions on Networking, vol.8 number 3", pages 281-293, 2000.
- 10
-
Peter Fankhauser, Gerald Huck and Ingo Macherius
"Components for Data Intensive XML Applications"
ERCIM News No.41 - April 2000
- 11
-
Gnutella,
http://gnutella.wego.com.
- 12
-
Groove Networks
http://www.groove.net/.
- 13
-
Google
http://www.google.com/.
- 14
-
IBM alphaWorks,
XML Parser for Java,
http://www.alphaworks.ibm.com/tech/xml4j/
- 15
-
M. Jovanovic,
"Modeling Large-scale Peer-to-Peer Networks and a case study of Gnutella",
Master's Thesis, University of Cincinati, April 2001.
- 16
-
Kazaa,
http://www.kazaa.com
- 17
-
James F. Kurose and Keith W. Ross
"Computer Networking: A Top-Down Approach Featuring the Internet"
pages 286-289, Addison Wesley Longman 1999
- 18
-
Leda,
Algorithmic Solutions Software GmbH,
http://www.mpi-sb.mpg.de/LEDA.
- 19
-
Q. Lv, P. Cao, E. Cohen, K. Li, and S. Shenker.
"Search and replication in unstructured peer-to-peer networks",
ICS02, New York, USA, June 2002.
- 20
-
V. Kalogeraki, D. Gunopulos and D. Zeinalipour-Yazti
Proceedings of the ACM CIKM International Conference on Information and Knowledge Management (CIKM), McLean, VA, USA, pages: 300-307, November 2002 - 21
-
Ken Mccrary,
"The JTella Java API for the Gnutella network",
October 2000,
http://www.kenmccrary.com/jtella/.
- 22
-
Stanley Milgram
Milgram's experiment description, available at:
http://smallworld.sociology.columbia.edu/description.html.
- 23
-
Napster,
http://www.napster.com.
- 24
-
Stephen North, Emden Gansner, John Ellson,
"Graphviz - open source graph drawing software",
http://www.research.att.com/sw/tools/graphviz/
- 25
-
REUTERS-21578 dataset.
http://www.research.att.com/ lewis
- 26
-
M.Ripeanu,
"Peer-to-peer Architecture Case Study: Gnutella Network",
Technical Report, University of Chicago, 2001.
- 27
-
I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, H. Balakrishnan.
Chord: A scalable peer-to-peer lookup service for Internet applications.
Proc. of ACM SIGCOMM, pages 149-160, August 2001.
- 28
-
B. Yang and H. Garcia-Molina,
Comparing hybrid peer-to-peer systems.
Proc. 27th Int. Conf. on Very Large Data Bases (Rome), pages 561-570, September 2001.
- 29
-
B. Yang, H. Garcia-Molina,
Efficient Search in Peer-to-Peer Networks.
Proc. Int. Conf. on Distributed Computing Systems, 2002.
- 30
-
D. Zeinalipour-Yazti and T. Folias,
"Quantitative Analysis of the Gnutella Network Traffic",
Dept. of Computer Science, University of California, Riverside, June 2000
footnotes
- ... parameter*
- In our experiments we used a fraction of 0.5 (a peer propagates the request to half its peers, selected at random).
- ... key*
-
Freenet uses a 160-bit SHA-1 [1] hash function
- ... key*
- The reason why they use such an approach is that newly inserted files are placed on nodes already possessing files with similar keys, which therefore yields a topology where nodes with similar keys are clustered together.
- ...Nodes*
- The hashing is based on the IP of the node
- ... Objects*
- The hashing is based on the object itself and the result is refereed as key
- ... network*
- In the event of the
 node join only O(1/N) keys/data are moved around
node join only O(1/N) keys/data are moved around
- ... peers*
- In our experiments we additionally select 1 random peer.