Projects
Mining Historical Manuscripts with Local Color Patches (ICDM 2010)


Fast and Flexible Multivariate Time-Series Search (ICDM 2010, work with NASA Ames Research Center)
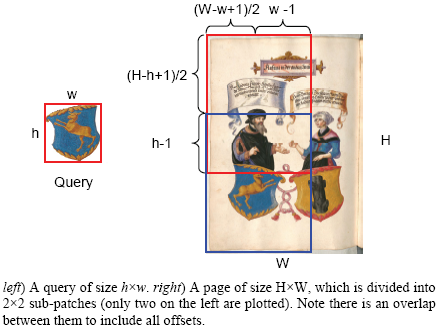
- Focused on local region-of-interest patches, other than the common global atomic images
- Introduced a simple color measure which both addresses and exploits the rich color information of images in historical manuscripts
- Proposed a novel and tight lower bound for color matching, to cheaply prune off unpromising candidatesto and enable the efficient mining of massive archives
- Built several highler-level data mining tools including motif discovery and link analyses, beyond the fast similarity search
- Demonstrated on extensive manuscripts dating back to the fifteenth century
- Designed an image retrieval framework which utilizes both the existing web image search engine and our color distance measurement
Fast and Flexible Multivariate Time-Series Search (ICDM 2010, work with NASA Ames Research Center)
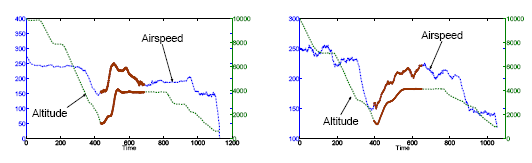
- Conducted the first work of MTS subsequence matching supporting queries on any subset of variables with time-shifting between them
- Designed a novel indexing method allowing fast search on very large datasets (the C-MAPSS and Conex datasets we indexed are much larger than any other datasets considered in the literature of time-series subsequence search)
- Algorithms and codes will be used within multiple NASA projects, including the Integrated Vehicle Health Management project
Using CAPTCHAs to Index
Cultural Artifacts (IDA 2010)
Mining and Indexing of Petroglyphs (KDD 2009, CAA 2009, DMKD 2010)

Exact Discovery of Time Series Motifs (SDM 2009, DMKD 2010)
Interactive and Intelligent Searching of Biological Images

Surface Depth Hallucination

Credit Evaluation of Banking Customers
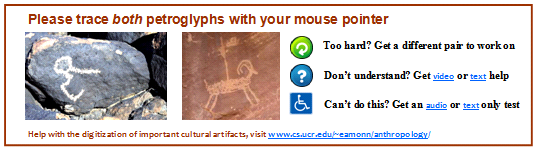
- Proposed a novel language-independent CAPTCHA which considers inherently real-valued data (photographs of rock art) and expects real-valued responses (mouse movements)
- The first real-valued-response CAPTCHA for crowdsourcing in data mining
- Very easy for humans, but extremely hard or even impossible for current machines
- Human efforts spent solving the CAPTCHAs (usually wasted) now can be utilized on another Human Computation project, which helps to extract useful data from incredibly heterogeneous and noisy datasets
- Made indexing all the world’s rock art possible
Mining and Indexing of Petroglyphs (KDD 2009, CAA 2009, DMKD 2010)
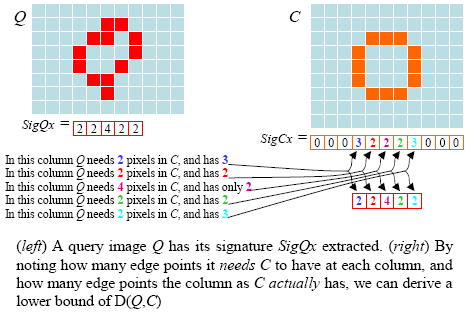
- Considered, for the first time, the problem of data mining large collections of rock art
- Introduced an explicit framing of Generalized Hough Transform (GHT) as the similarity measure
- Estimated a lower bound distance based on one dimensional signatures extracted from original data
- Proposed algorithms which allow efficient and effective mining of rock art, e.g.: finding repeated motifs, clustering, and enabling query-by-content
- Working on supporting rotation
invariance and partial
shape matching
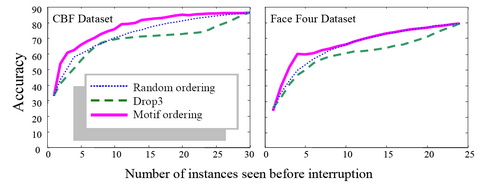
Exact Discovery of Time Series Motifs (SDM 2009, DMKD 2010)
- Presented a tractable exact algorithm to find time series motifs, which are most similar pairs of time series
- Faster than all current approximate algorithms and up to three orders of magnitude faster than the brute-force search in large datasets
- Proposed a novel use of time series motifs in anytime classification
Interactive and Intelligent Searching of Biological Images
- Focused on identification of nematodes, which are particularly difficult to identify and have direct and significant effect on humans
- Constructed multiple graphs for nematodes based on different features and similarity functions
- Built an interactive navigator (use guest/guest to login) which makes nematode identification a simple process of point and click
Surface Depth Hallucination
- Implemented a perceptually validated model for depth hallucination
- Enabled acquiring surface detail for texturing by a standard digital camera
- Estimated a 3D model that can be viewed from any angle under any illumination using two single-view 2D images
- Source code, user manual, etc can be downloaded here
Credit Evaluation of Banking Customers
- Constructed a hybrid evaluation model based on clustering (SOM and K-means) and probabilistic neural network (PNN)
- Performed better than simplex PNN and other 14 classic evaluation models on two standard datasets