This lab will be based on ns. First we will explain how to use commands of ns and create tcl files. Then you will be responsible for building a simple scenerio and make some post simulation analysis.
The following lines describe the basic functions that you can use in a .tcl file to build a scenerio and generate traffic on it.
- set ns [new Simulator]: generates an NS
simulator object instance, and assigns it to variable ns (italics
is used for variables and values in this section). What this line does is
the following:
- Initialize the packet format (ignore this for now)
- Create a scheduler (default is calendar scheduler)
- Select the default address format (ignore this for now)
- Create compound objects such as nodes and links (described later)
- Connect network component objects created (ex. attach-agent)
- Set network component parameters (mostly for compound objects)
- Create connections between agents (ex. make connection between a "tcp" and "sink")
- Specify NAM display options
- Etc.
- $ns color fid color: is to set
color of the packets for a flow specified by the flow id (fid). This member
function of "Simulator" object is for the NAM display, and has no effect
on the actual simulation.
- $ns namtrace-all file-descriptor:
This member function tells the simulator to record simulation traces in
NAM input format. It also gives the file name that the trace will be written
to later by the command $ns flush-trace.
Similarly, the member function trace-all is for
recording the simulation trace in a general format.
- proc finish {}: is called after this simulation
is over by the command $ns at 5.0 "finish".
In this function, post-simulation processes are specified.
- set n0 [$ns node]: The member function
node creates a node. A node in NS is compound object
made of address and port classifiers (described in a later section). Users
can create a node by separately creating an address and a port classifier
objects and connecting them together. However, this member function of Simulator
object makes the job easier. To see how a node is created, look at the files:
"ns-2/tcl/libs/ns-lib.tcl" and "ns-2/tcl/libs/ns-node.tcl".
- $ns duplex-link node1 node2 bandwidth delay
queue-type: creates two simplex links of specified bandwidth
and delay, and connects the two specified nodes. In NS, the output queue
of a node is implemented as a part of a link, therefore users should specify
the queue-type when creating links. In the above simulation script, DropTail
queue is used. If the reader wants to use a RED queue, simply replace the
word DropTail with RED. The NS implementation of a link is shown in a later
section. Like a node, a link is a compound object, and users can create
its sub-objects and connect them and the nodes. Link source codes can be
found in "ns-2/tcl/libs/ns-lib.tcl" and "ns-2/tcl/libs/ns-link.tcl" files. One thing to note is that
you can insert error modules in a link component to simulate a lossy link
(actually users can make and insert any network objects). Refer to the NS
documentation to find out how to do this.
- $ns queue-limit node1 node2 number:
This line sets the queue limit of the two simplex links that connect node1
and node2 to the number specified. At this point, the authors do not know
how many of these kinds of member functions of Simulator objects are available
and what they are. Please take a look at "ns-2/tcl/libs/ns-lib.tcl" and "ns-2/tcl/libs/ns-link.tcl", or NS documentation for more information.
- $ns duplex-link-op node1 node2 ...: The next couple of lines are used for the NAM display. To see the effects of these lines, users can comment these lines out and try the simulation.
Now that the basic network setup is done, the next thing to do is to setup traffic agents such as TCP and UDP, traffic sources such as FTP and CBR, and attach them to nodes and agents respectively.
- set tcp [new Agent/TCP]: This line
shows how to create a TCP agent. But in general, users can create any agent or
traffic sources in this way. Agents and traffic sources are in fact basic
objects (not compound objects), mostly implemented in C++ and linked to OTcl.
Therefore, there are no specific Simulator object member functions that create
these object instances. To create agents or traffic sources, a user should
know the class names these objects (Agent/TCP, Agnet/TCPSink, Application/FTP
and so on). This information can be found in the NS documentation or partly in
this documentation. But one shortcut is to look at the "ns-2/tcl/libs/ns-default.tcl" file. This file contains the
default configurable parameter value settings for available network objects.
Therefore, it works as a good indicator of what kind of network objects are
available in NS and what are the configurable parameters.
- $ns attach-agent node agent: The
attach-agent member function attaches an agent object
created to a node object. Actually, what this function does is call the attach member function of specified node, which attaches
the given agent to itself. Therefore, a user can do the same thing by, for
example, $n0 attach $tcp. Similarly, each agent
object has a member function attach-agent that
attaches a traffic source object to itself.
- $ns connect agent1 agent2: After two agents that will communicate with each other are created, the next thing is to establish a logical network connection between them. This line establishes a network connection by setting the destination address to each others' network and port address pair.
Assuming that all the network configuration is done, the next thing to do is write a simulation scenario (i.e. simulation scheduling). The Simulator object has many scheduling member functions. However, the one that is mostly used is the following:
- $ns at time "string": This member function of a Simulator object makes the scheduler (scheduler_ is the variable that points the scheduler object created by [new Scheduler] command at the beginning of the script) to schedule the execution of the specified string at given simulation time. For example, $ns at 0.1 "$cbr start" will make the scheduler call a start member function of the CBR traffic source object, which starts the CBR to transmit data. In NS, usually a traffic source does not transmit actual data, but it notifies the underlying agent that it has some amount of data to transmit, and the agent, just knowing how much of the data to transfer, creates packets and sends them.
After all network configuration, scheduling and post-simulation procedure specifications are done, the only thing left is to run the simulation. This is done by $ns run.
The above example and information come from the Worcester Polytechnic Institute and from the site
Ns by Example. There you can find many
examples for Ns Simulator and additional resources.
Trace Analysis Example
This section shows a trace analysis example. Trace_Example is the same OTcl script as the one in the "Simple Simulation Example" section with a few lines added to open a trace file and write traces to it. For the network topology it generates the simulation scenario, refer to last weeks figure. To run this script download "ns-simple-trace.tcl" and type "ns ns-simple-trace.tcl" at your shell prompt.

Trace_Example. Trace Enabled Simple NS Simulation Script (modified from Example ns-simple.tcl)
Running the above script generates a NAM trace file that is going to be used as an input to NAM and a trace file called "out.tr" that will be used for our simulation analysis. Following figure shows the trace format and example trace data from "out.tr".
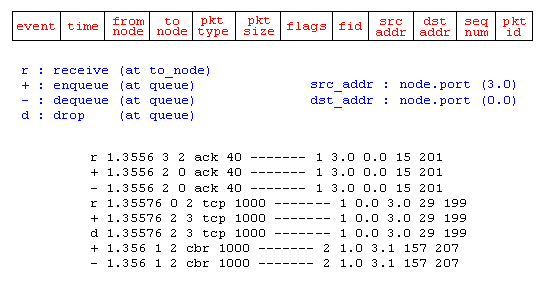
Trace Format Example
Each trace line starts with an event (+, -, d, r) descriptor followed by the simulation time (in seconds) of that event, and from and to node, which identify the link on which the event occurred. The next information in the line before flags (appeared as "------" since no flag is set) is packet type and size (in Bytes). Currently, NS implements only the Explicit Congestion Notification (ECN) bit, and the remaining bits are not used. The next field is flow id (fid) of IPv6 that a user can set for each flow at the input OTcl script. Even though fid field may not used in a simulation, users can use this field for analysis purposes. The fid field is also used when specifying stream color for the NAM display. The next two fields are source and destination address in forms of "node.port". The next field shows the network layer protocol's packet sequence number. Note that even though UDP implementations do not use sequence number, NS keeps track of UDP packet sequence number for analysis purposes. The last field shows the unique id of the packet.
Having simulation trace data at hand, all one has to do is to transform a subset of the data of interest into a comprehensible information and analyze it.
Programming Assignment
Part 1
Build a simple network that consists of 4 nodes connected in a linear topology. The detailed specifications of the network are:
- Node0 will be connected with Node1 with a duplex link. The link has 1.5 Mbps of bandwidth and 20 ms of delay.
- Node1 is connected with Node2 with a duplex link of 1 Mbps bandwidth and 20 ms of delay.
- Node2 will be connected with Node3 with a duplex link. The link has 1.5 Mbps of bandwidth and 20 ms of delay.
- The queue size of the links Node1-Node2 and Node2-Node3 is 150
Plot the size of the queue in Node1 and Node2 as a function of time (Tip: Compute the size of the queue in intervals of 0.1 seconds).